Using a Pivot Table
Problem
Support for a sequence of elements is often needed to solve various SQL problems. For example, given a range of dates, you may wish to generate one row for each date in the range. Or, you may wish to translate a series of values returned in separate rows into a series of values in separate columns of the same row. To implement such functionality, you can use a permanent table that stores a series of sequential numbers. Such a table is referred to as a Pivot table.
Many of the recipes in our book use a Pivot table, and, in all cases, the table's name is Pivot. This recipe shows you how to create that table.
Solution:
First, create the Pivot table. Next, create a table named Foo that will help you populate the Pivot table:
CREATE TABLE Pivot (i INT,PRIMARY KEY(i))
CREATE TABLE Foo(i CHAR(1))
The Foo table is a simple support table into which you should insert the following 10 rows:
INSERT INTO Foo VALUES('0')
INSERT INTO Foo VALUES('1')
INSERT INTO Foo VALUES('2')
INSERT INTO Foo VALUES('3')
INSERT INTO Foo VALUES('4')
INSERT INTO Foo VALUES('5')
INSERT INTO Foo VALUES('6')
INSERT INTO Foo VALUES('7')
INSERT INTO Foo VALUES('8')
INSERT INTO Foo VALUES('9')
Using the 10 rows in the Foo table, you can easily populate the Pivot table with 1,000 rows. To get 1,000 rows from 10 rows, join Foo to itself three times to create a Cartesian product:
INSERT INTO Pivot SELECT f1.i+f2.i+f3.i FROM Foo f1, Foo F2, Foo f3
If you list the rows of Pivot table, you'll see that it has the desired number of elements and that they will be numbered from 0 through 999.
You can generate more rows by increasing the number of joins. Join Foo four times, and you'll end up with 10,000 rows (10 * 10 * 10 * 10).
Discussion:
The Pivot table is often used to add a sequencing property to a query. Some form of Pivot table is found in many SQL-based systems, though it is often hidden from the user and used primarily within predefined queries and procedures.
You've seen how the number of table joins (of the Foo table) controls the number of rows that our INSERT statement generates for the Pivot table. The values from 0 through 999 are generated by concatenating strings. The digit values in Foo are character strings. Thus, when the plus (+) operator is used to concatenate them, we get results such as the following:
'0' + '0' + '0' = '000'
'0' + '0' + '1' = '001'
..
These results are inserted into the INTEGER column in the destination Pivot table. When you use an INSERT statement to insert strings into an INTEGER column, the database implicitly converts those strings into integers. The Cartesian product of the Foo instances ensures that all possible combinations are generated, and, therefore, that all possible values from 0 through 999 are generated.
It is worthwhile pointing out that this example uses rows from 0 to 999 and no negative numbers. You could easily generate negative numbers, if required, by repeating the INSERT statement with the "-" sign in front of the concatenated string and being a bit careful about the 0 row. There's no such thing as a -0, so you wouldn't want to insert the '000' row when generating negative Pivot numbers. If you did so, you'd end up with two 0 rows in your Pivot table. In our case, two 0 rows are not possible, because we define a primary key for our Pivot table.
The Pivot table is probably the most useful table in the SQL world. Once you get used to it, it is almost impossible to create a serious SQL application without it. As a demonstration, let us use the Pivot table to generate an ASCII chart quickly from the code 32 through 126:
SELECT i Ascii_Code, CHAR(i) Ascii_Char FROM Pivot WHERE i BETWEEN 32 AND 126
Ascii_Code Ascii_Char
---------- ------------
32 space
33 !
34 "
35 #
36 $
37 %
38 &
39 '
40 (
41 )
42 *
43 +
44 ,
45 -
46 .
47 /
48 0
49 1
50 2
51 3
What's great about the use of the Pivot table in this particular instance is that you generated rows of output without having an equal number of rows of input. Without the Pivot table, this is a difficult, if not impossible, task. Simply by specifying a range and then selecting Pivot rows based on that range, we were able to generate data that doesn't exist in any database table.
You must have enough Pivot table rows to accommodate the range that you specify. Had we used BETWEEN 32 AND 2000, our query would have failed, because our Pivot table has only 1,000 rows, not the 2,001 that would be required by such a large range.
As another example of the Pivot table's usefulness, we can use it easily to generate a calendar for the next seven days:
SELECT CONVERT(CHAR(10),DATEADD(d,i,CURRENT_TIMESTAMP), 121) date,DATENAME(dw,DATEADD(d,i,CURRENT_TIMESTAMP)) day FROM Pivot WHERE i BETWEEN 0 AND 6
date day
---------- -------------------
2001-11-05 Monday
2001-11-06 Tuesday
2001-11-07 Wednesday
2001-11-08 Thursday
2001-11-09 Friday
2001-11-10 Saturday
2001-11-11 Sunday
These two queries are just quick teasers, listed here to show you how a Pivot table can be used in SQL. As you'll see in other recipes, the Pivot table is often an indispensable tool for quick and efficient problem solving.
SQL Server Architecture
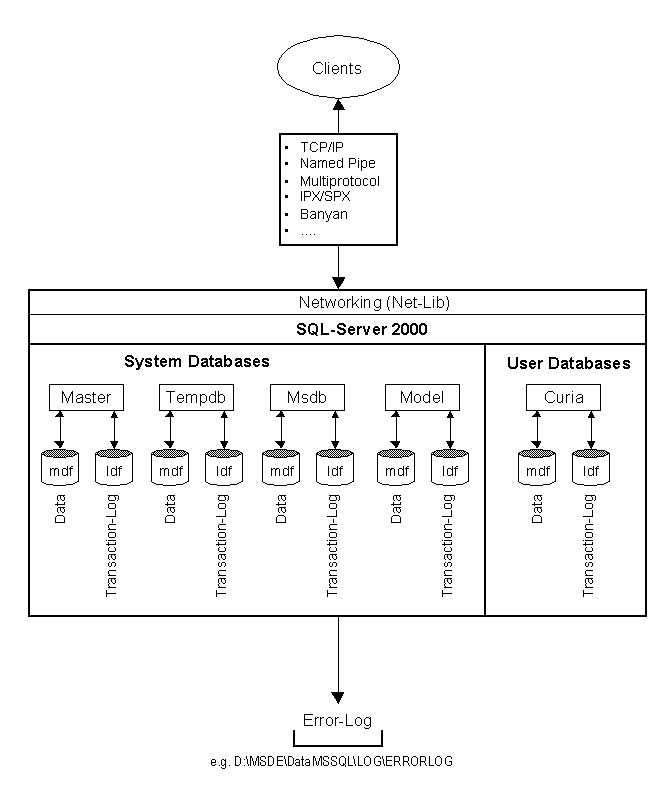
Microsoft® SQL Server data is stored in databases. The data in a database is organized into the logical components visible to users. A database is also physically implemented as two or more files on disk.
When using a database, you work primarily with the logical components such as tables, views, procedures, and users. The physical implementation of files is largely transparent. Typically, only the database administrator needs to work with the physical implementation.
Each instance of SQL Server has four system databases (master, model, tempdb, and msdb) and one or more user databases. Some organizations have only one user database, containing all the data for their organization. Some organizations have different databases for each group in their organization, and sometimes a database used by a single application. For example, an organization could have one database for sales, one for payroll, one for a document management application, and so on. Sometimes an application uses only one database; other applications may access several databases.
It is not necessary to run multiple copies of the SQL Server database engine to allow multiple users to access the databases on a server. An instance of the SQL Server is capable of handling thousands of users working in multiple databases at the same time. Each instance of SQL Server makes all databases in the instance available to all users that connect to the instance, subject to the defined security permissions.
When connecting to an instance of SQL Server, your connection is associated with a particular database on the server. This database is called the current database. You are usually connected to a database defined as your default database by the system administrator.
SQL Server allows you to detach databases from an instance of SQL Server, then reattach them to another instance, or even attach the database back to the same instance. If you have a SQL Server database file, you can tell SQL Server when you connect to attach that database file with a specific database name.
When using a database, you work primarily with the logical components such as tables, views, procedures, and users. The physical implementation of files is largely transparent. Typically, only the database administrator needs to work with the physical implementation.
Each instance of SQL Server has four system databases (master, model, tempdb, and msdb) and one or more user databases. Some organizations have only one user database, containing all the data for their organization. Some organizations have different databases for each group in their organization, and sometimes a database used by a single application. For example, an organization could have one database for sales, one for payroll, one for a document management application, and so on. Sometimes an application uses only one database; other applications may access several databases.
It is not necessary to run multiple copies of the SQL Server database engine to allow multiple users to access the databases on a server. An instance of the SQL Server is capable of handling thousands of users working in multiple databases at the same time. Each instance of SQL Server makes all databases in the instance available to all users that connect to the instance, subject to the defined security permissions.
When connecting to an instance of SQL Server, your connection is associated with a particular database on the server. This database is called the current database. You are usually connected to a database defined as your default database by the system administrator.
SQL Server allows you to detach databases from an instance of SQL Server, then reattach them to another instance, or even attach the database back to the same instance. If you have a SQL Server database file, you can tell SQL Server when you connect to attach that database file with a specific database name.
Subscribe to:
Posts (Atom)
